I was an original owner of a SPARCstation IPX back in 1993, running SunOS 4.1.3. It was my home machine — I’d sold my Mac because I was really geeking out on programming and wanted to go all in. I remember that machine as blazing fast, especially through a software engineer’s eyes.
When I started my collection, the IPX was the first machine in the Unix world I restored, because it had high sentimental value. During that restoration it was much easier to find install media for Solaris 2.6, so that’s what I went with.

I was shocked how slow the box felt. My first thought was that the SCSI2SD/ZuluSCSI was the bottleneck, but I quickly figured out that wasn’t the case. So I really put my back into getting 4.1.3 and then 4.1.4 installed and working.
I was shocked how fast the box was.
The same thing has played out on every SS-class box I’ve put on the bench since. Which is why I run 4.1.4 on all of them and host bootable disk images for anyone wanting to try the same.
Boot a SPARCstation IPX with a clean SunOS 4.1.4
install and you get a fast, responsive Unix box. Boot the same
machine with Solaris 2.6 and it feels like wading
through molasses. Login takes longer. The shell is
laggier. Even running ls in a directory you’ve
already cached feels somehow slower.
Why is 2.6 so much slower? I get this question a lot — usually from people who write in asking for a bootable 2.6 image for their SS1.
The short answer is that Solaris 2 brought a different I/O architecture along with it - System V Release 4 STREAMS - and that architecture imposes a real per-packet cost that the older BSD-based stack in SunOS 4 doesn’t pay. On hardware sized for the older, lighter system, the difference shows up as exactly the kind of pervasive sluggishness that’s hard to point at but impossible to miss.
The architectural fork
In 1987, Sun and AT&T signed a partnership to merge BSD Unix and System V into a unified Unix - what became SVR4. That deal is the reason Solaris 2 exists at all, and it’s also the reason Solaris 2 feels different from SunOS 4 in ways that go deeper than version numbers.
SunOS 4 is BSD. Specifically, it’s 4.3BSD-Tahoe-ish with Sun’s additions on top. The kernel architecture, the networking code, the tty subsystem, the filesystem internals - all of it traces directly back to Berkeley. If you’ve read the Stevens books, you’ve basically read the SunOS 4 source code.
Solaris 2 is SVR4. The kernel was substantially rewritten around System V semantics, with BSD compatibility layered on top via the BSD/SunOS Compatibility Package. The networking moved from BSD’s mbuf-based stack to SVR4 STREAMS. The init system changed. Packaging changed. Even the device naming conventions changed.
That’s a much bigger change than just “newer version.” It’s a different operating system that happens to share a lot of source-level compatibility with the old one. And the I/O architecture it brought along is the main reason SS-class hardware feels wrong running it.
What an mbuf actually is
Before getting to STREAMS, it’s worth understanding what BSD networking does, because it’s beautiful in its own way and Stevens spends most of Vol 2 explaining it.

An mbuf is a small fixed-size buffer. In 4.4BSD it’s
128 bytes. The mbuf has a small header containing a
few pointers - m_next for the next mbuf in this
packet, m_nextpkt for the next packet in a queue,
m_len for the data length, m_data pointing at
where the actual data lives.
The clever part is that mbufs chain together to represent a single packet. A 1500-byte ethernet frame might be one mbuf with a “cluster” (an external 2KB buffer) holding the payload, plus a couple of small mbufs prepended for protocol headers. When TCP wants to add its 20-byte header to a payload, it doesn’t copy anything - it just allocates a fresh mbuf, fills in the header, and links it to the front of the chain. The packet grows by linking, not copying.
Stevens devotes Chapter 2 of Vol 2 to mbufs. His
Figure 2.1 captures the four shapes the same mbuf{}
structure can take, depending on the m_flags value:
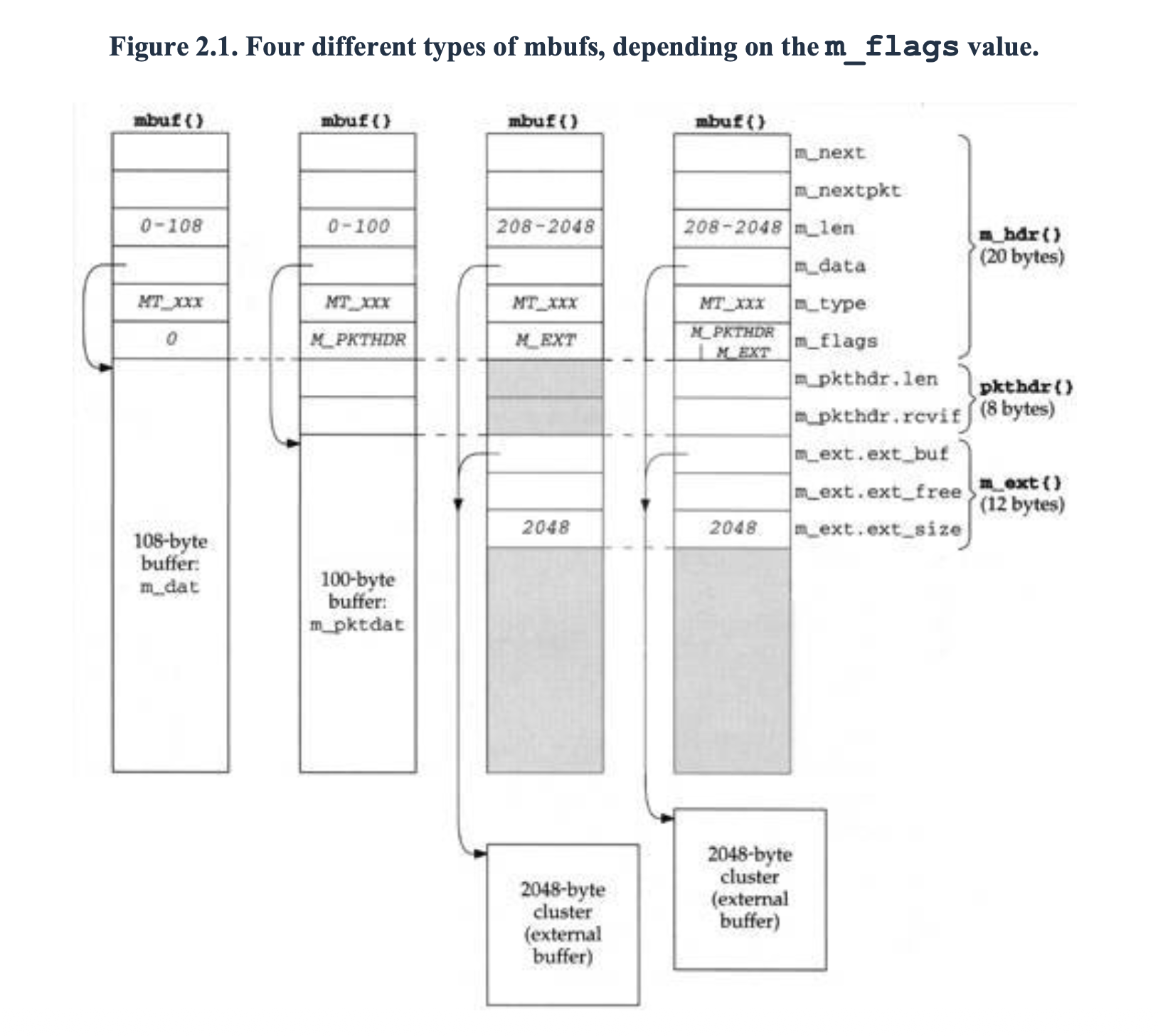
From left to right: a plain 108-byte mbuf, an mbuf
with M_PKTHDR (the 100-byte version that holds
per-packet metadata in m_pkthdr), an mbuf with
M_EXT whose m_data points at a separate 2 KB
cluster, and the combination — packet header plus
cluster, the shape an incoming Ethernet frame
typically takes. The diagrams of mbuf chains built
out of these shapes are some of the clearest
illustrations of BSD networking I’ve seen anywhere.
The properties that matter for performance:
- Prepending headers is free. Just allocate a small mbuf and link it.
- Big payloads use external clusters. A 1500-byte packet isn’t fragmented across 12 mbufs.
- Layers communicate by direct function calls. The
ethernet input routine calls
ip_input()directly. IP callstcp_input()directly. No queues, no scheduling decisions. - Memory comes from a dedicated freelist. Allocation is fast and predictable.
The cost model is essentially: a packet’s journey through the stack is N function calls and zero copies. On the IPX’s 40 MHz SPARC, this is wickedly efficient.
The send and receive paths
Stevens walks through the receive path in detail in Vol 2 Chapter 4 (interface layer) through Chapter 28 (TCP input). The compressed version:
- NIC raises an interrupt
- Driver’s interrupt handler runs in interrupt context, pulls the frame off the card into an mbuf chain
- Driver calls
ether_input()or its equivalent, which dispatches based on ethertype ether_input()callsip_input()directlyip_input()validates headers, makes routing decisions, callstcp_input()directlytcp_input()finds the matching socket via the PCB hash, processes the segment, appends the payload to the socket receive buffer, possibly wakes a sleeping reader- Interrupt returns
That whole chain - wire to socket buffer - happens in
a single interrupt context. The kernel doesn’t
yield, doesn’t schedule, doesn’t preempt itself. It
enters at the NIC interrupt and exits when the packet
is sitting in a socket buffer ready for read().
Function call, function call, function call, done.
The send path is symmetric. A write() syscall traps
in, copies user data into mbufs, walks down through
TCP, IP, the route table, ARP, the driver, and into
the NIC’s transmit ring, all in one syscall context.
This is what I mean when I say the BSD model “does more in one context.” The kernel grabs the CPU when a packet arrives, holds it through every layer of protocol processing, and only lets go when the work is done. There are no scheduling boundaries inside the stack.
Stevens’ Figure 1.12 maps the whole architecture in
one picture — the hardware interrupt at splimp that
pulls a packet off the wire, the protocol layer that
runs at splnet, the function calls that send a
packet back down, and the queues that connect them:
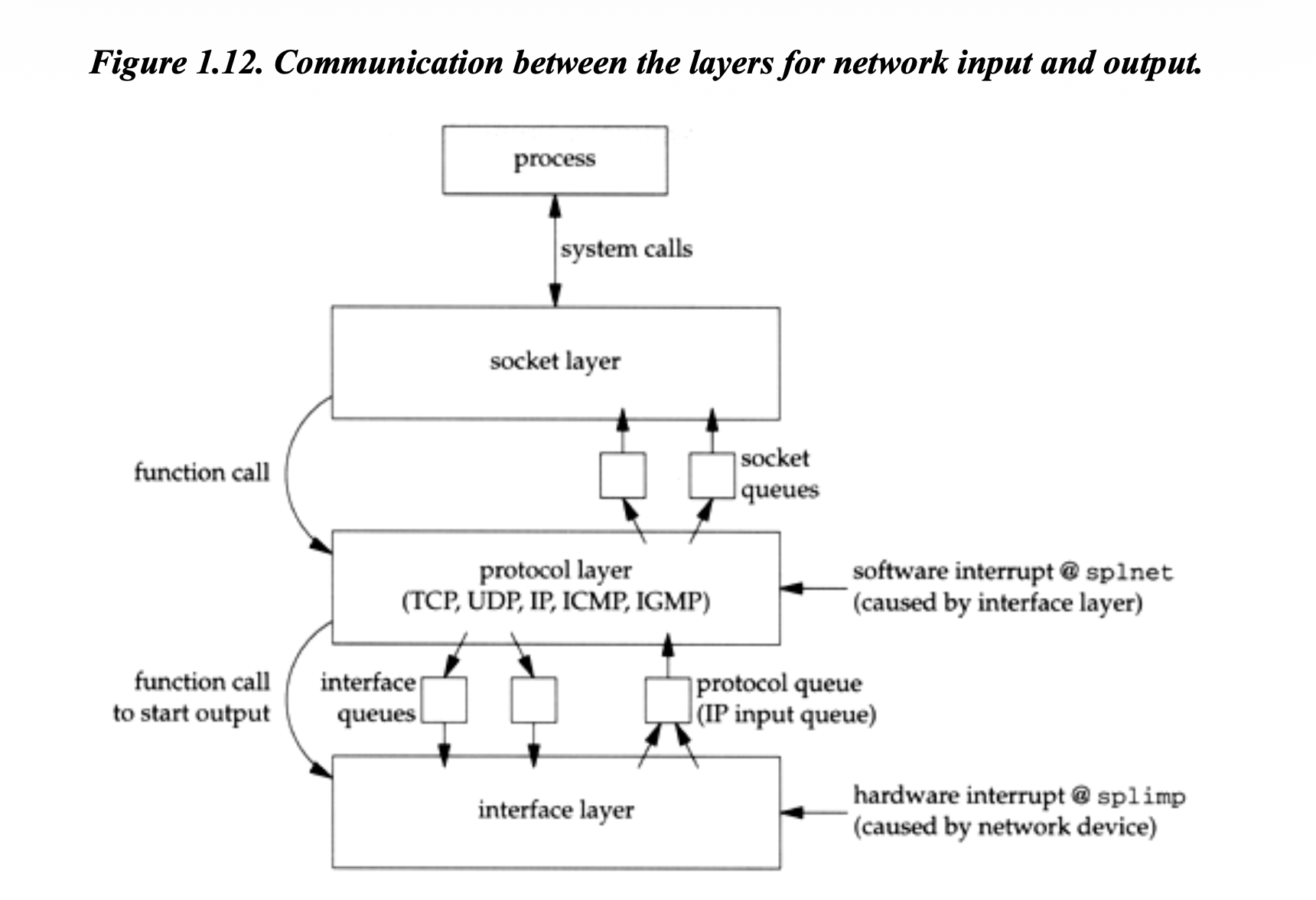
What STREAMS does instead
STREAMS came from Dennis Ritchie’s research at Bell Labs - the original paper is from 1984 - and got incorporated into SVR3 and then SVR4. The motivation was different from BSD’s. Ritchie wasn’t trying to build a fast TCP/IP stack; he was trying to build a flexible, modular, dynamically-reconfigurable I/O subsystem where protocol layers could be pushed and popped at runtime.
In STREAMS, a stream is a bidirectional pipeline of
modules. Each module has a read queue and a write
queue. Modules communicate by passing messages
(mblk_t/dblk_t pairs) up and down the stream. You can
I_PUSH a module onto a stream at runtime, which is
genuinely useful for things like tty line disciplines.
The model has some real virtues:
- Modules are pluggable at runtime
- Flow control between layers is built into the framework
- The interface is uniform - everything’s a stream
- You can intercept and instrument at module boundaries
The cost is at every module boundary. When the IP
module wants to hand a packet to TCP, it doesn’t call
tcp_input(). It calls putnext(), which either runs
TCP’s put() routine immediately or enqueues the
message and schedules TCP’s service routine to run
later. Either way, there’s framework overhead that
BSD’s direct function calls don’t pay.
The SVR4 networking stack puts everything inside
STREAMS. The IP module is a STREAMS module. TCP and
UDP are STREAMS modules. The socket layer in Solaris
2 is implemented on top of STREAMS via an emulation
layer (sockmod). Every packet traversing the stack
goes through multiple putnext() calls, queue
operations, and potentially scheduler decisions.
For tty handling, all this is fine. Pushing ldterm
and ptem onto a pty stream is exactly the kind of
thing STREAMS is good at. For TCP/IP, where the
layering is fixed for the life of the connection and
the hot path is performance-critical, you’re paying
for flexibility you never use.
Why it shows up as feel
You’d think this would only affect networking benchmarks, but it shows up in interactive feel for two reasons.
First, on a single-CPU IPX with 32MB of RAM, the heavier networking stack means more kernel memory occupied, more code paths exercised on every packet, and more cache pressure. The kernel itself is just bigger in Solaris 2 - more daemons running, more kernel modules loaded, more memory committed to data structures - and that crowds out the userspace working set you actually care about. On a 32 MB box, this kernel-weight effect probably matters as much as the per-packet STREAMS cost itself — both are real, and they compound.
Second, every operation on a Sun workstation involves the network stack somehow. NFS for the home directory, NIS for password lookups, syslog over the network if you’re configured that way. There’s no escape path that avoids the I/O architecture. So the per-packet overhead compounds across every interactive operation.
Stevens’ TCP/IP Illustrated Vol 1 has a great
section showing what happens at the packet level when
you do something as simple as rlogin to another
machine. A single keystroke triggers four TCP
segments — your character, the server’s echo, and an
ACK in each direction — each one traversing the full
stack down on the sender and back up on the receiver.
On a SunOS 4 box those traversals run at near-wire-
speed CPU cost. On Solaris 2.6, each one pays STREAMS
tax going up and going down. Multiply by every
keystroke and you’re feeling it.
The other side: under load
Here’s the twist that makes the architectural debate interesting rather than a simple “BSD won” story.
The same property that makes BSD fast at light load makes it fall apart at heavy load. When packets are arriving at high rates, the BSD stack stays in interrupt context longer and longer per second. Because protocol processing all happens at network IPL, userspace can’t run while the kernel is processing packets. Worse, lower-priority interrupts (like the keyboard) get blocked too.
This is the famous “receive livelock” problem, documented by Mogul and Ramakrishnan in their 1996 paper “Eliminating Receive Livelock in an Interrupt-Driven Kernel.” Under high packet rates, throughput on a BSD stack can actually decrease as load increases - the kernel spends all its time pulling packets out of the NIC and processing them through the stack, but the userspace processes that need to read from the socket buffers can’t get scheduled, so the buffers fill up, packets get dropped, the senders retransmit, and you get more packets to process. A real failure mode for busy SunOS 4 NFS servers in the early 90s.
A heavily loaded SunOS 4 box has a very
characteristic feel: the load average is low, top
shows nothing using CPU, but the console is
unresponsive and shells timeout. (top isn’t part of
stock SunOS 4 — I keep GNU top installed on my
boxes for exactly this kind of diagnostic moment.)
It’s pegged in interrupt context handling network
traffic and there’s nothing useful you can do to see
it.
Solaris 2.6, with all its STREAMS overhead, doesn’t fall over the same way. STREAMS’ message-passing model means packet processing happens at lower priority than the raw interrupt handler, with scheduling boundaries that let userspace get CPU time even when network traffic is heavy. It’s slower at light load and lower peak throughput, but it degrades much more gracefully under sustained load. The console stays usable when an IPX running SunOS 4 would be effectively frozen.
So the architectural debate isn’t actually one-sided. BSD is optimized for the common case - one packet at a time, light to moderate load, snappy desktop - and pays for that under sustained heavy load. STREAMS is optimized for fairness and graceful degradation, and pays for that on every single packet. Different design centers, different tradeoffs.
How Linux split the difference
Linux ended up in the BSD camp on this one — sk_buff
is essentially a modernized mbuf, FreeBSD never
adopted STREAMS, and macOS (NeXT/BSD lineage) uses
mbufs too. But Linux didn’t ignore the load-handling
problem either: softirqs defer protocol processing
out of interrupt context, NAPI switches the driver to
polled mode under heavy load, and per-CPU queues
spread work across cores. The fast path stays inline
and fast; the deferral mechanisms only kick in when
load demands them.
This is, I think, the right answer in retrospect. STREAMS over-corrected by adding scheduling boundaries everywhere. Modern Linux gets the BSD per-packet efficiency at light load and the STREAMS-like fairness at heavy load by being smart about which path to take dynamically.
What this means for vintage hardware
For a SPARCstation IPX sitting on my workbench running a small workload - one user, occasional NFS access, light X11 usage - SunOS 4.1.3_U1 or 4.1.4 is unambiguously the right OS. The hardware was designed for it, the networking stack was designed for it, and the interactive feel reflects what these machines were actually capable of in their prime. It’s the original BSD-flavored Unix at its most polished, on hardware that fits the OS like a glove. Stevens' books read like a love letter to that exact stack, and running it on real hardware while reading the code in Vol 2 is one of the great pleasures of vintage Sun ownership.
If I were running an IPX as a busy departmental NFS server in 1994 with twenty clients hammering it - which is honestly outside what an IPX was sized for anyway - Solaris 2.6 would feel sluggish but might actually serve clients more reliably under saturation. The console would be miserable but the workload would complete.
For SPARCstation 5 / 10 / 20 and Ultra-class machines like the Ultra 1 or Ultra 5, Solaris 2.x is the right call - those CPUs have the headroom to absorb STREAMS overhead and the workloads that historically ran on them often benefit from Solaris 2’s better SMP, better filesystems, and broader software support. But for the SS1 / SS2 / IPC / IPX class, SunOS 4 is the answer.
If you want to try this yourself, see Getting SunOS 4.1.4 Working for the install notes and post-install setup that make the system actually usable in 2026.
A footnote on Stevens
If you want to actually understand the BSD networking implementation in depth, TCP/IP Illustrated Vol 2 is the reference. It walks through 4.4BSD-Lite source code chapter by chapter, with annotated code listings and diagrams that make the structure of the stack visible in a way that’s hard to extract from the source alone.
For the protocol-level view of what’s actually traversing the wire, Vol 1 remains the canonical reference. Vol 3 covers TCP transactions, HTTP, NNTP, and Unix domain protocols and is more specialized but worth having if you find yourself in any of those areas.
Reading Vol 2 with a SunOS 4 source tree open beside it is something I’d recommend to anyone who wants to understand how Unix networking actually works. The code in the book and the code in SunOS 4 are close cousins - both descended from the same Berkeley lineage, with only Sun-specific additions distinguishing them. You can literally trace the data structures from the book to the running kernel on your bench.
Solaris 2 source isn’t readable in the same way. Most of the kernel was closed for the entire commercial life of the OS, and even with OpenSolaris and now illumos, the SVR4 STREAMS architecture is harder to understand from the code alone than from a good book. Sun’s STREAMS Programmer’s Guide is the closest thing to a definitive reference, but there’s nothing quite like Stevens for the BSD side.
If you’re serious about understanding BSD networking, TCP/IP Illustrated Vol 2 is a must-have on the shelf. Used copies turn up regularly on eBay, AbeBooks, and other used-book vendors — well worth tracking down.
Closing thought
The SunOS 4 vs Solaris 2 feel difference on a SPARCstation IPX is one of those rare cases where you can directly experience an architectural decision through the user interface. It’s not subtle, it’s not an artifact of the benchmark, it’s a real consequence of how the kernels are structured. The newer OS is heavier in ways that matter for modest hardware, and the older OS is lighter in ways that show up as snappiness.
It’s also a great illustration of why “newer is better” doesn’t always hold in systems software. Solaris 2 brought genuine improvements - better SMP, modular kernel, dynamically loadable drivers, eventual ZFS and DTrace and zones - that justified its weight on the hardware it was actually targeting. But on a SPARCstation IPX designed for SunOS 4, the weight is just weight. The OS is solving problems the hardware doesn’t have, at a cost the hardware can’t easily pay.
If you’ve got an IPX and you’re trying to decide what to run, the answer is SunOS 4.1.4. The machine will thank you, and so will Stevens.